チャットGPT騒動の本質とは何か
2022年11月の発表以来、チャットGPTは世界中の多くの人から注目され、賛否が議論され続けています。日本においては、チャットGPTに代表される生成AIを「過剰に」評価するか、あるいは「過剰に」恐れるという反応が見受けられますが、そのどちらも正確な理解や批評から私たちを遠ざけてしまいます。
まず指摘したいのは、AI開発の歴史は決して新しいものではないことです。1950年代から始まったAI開発は、これまで3度の開発ブームを経ています。特にこの10年ほどで米国を中心に政府・企業は生成AIのための機械学習に何百億ドルもの資金を投じてきました。もちろんビッグデータ収集によって機械学習に使われるデータの量が飛躍的に増えたことや、AIを駆動させる の開発によって、チャットGPTのような生成AIが誕生したことは注目すべきですが、新たな技術が突然登場したかのように驚くべきものではありません。
*アルゴリズム: 問題を解決したり目標を達成したりするための手順や計算方法。
*ターゲティング広告: ユーザーの属性やWebサイトの閲覧履歴といった情報を元に、ユーザーのニーズにあった内容を配信する広告。
チャットGPTは米国のオープンAI社が開発した「汎用大規模言語モデル(LIM)」です。簡単に言えば膨大なテキストデータを材料に、単語と単語の直接的なつながり具合の確率を調べて、それをもとにもっともらしい文章を自動生成する自然言語処理のソフトウェア技術です。人間と異なる点は、読み込んだ膨大な情報すべてを価値主観的な優先順位をつけずに処理するという点です。人間の書いた文章をコンピュータに理解させるという自然言語処理に、科学者や技術者は長年挑戦してきましたが、ようやく人間と会話ができるレベルに達した、といえるでしょう。
しかし、多くの人が実感しているように、現時点でチャットGPTが出す結果の文章は、およそ人間が書いたと思えない間違いやでたらめな内容ばかりです。これを単なる「過渡的なプロセス(=もっと時間をかけて機械学習が進めばいずれ人間が書いたものと同じような結果が出てくる)」ととらえる楽観論もあります。本当にそうでしょうか?
カナダのブロック大学教授でデータ・ガバナンスやインターネット・ガバナンスの専門家であるブレイン・ハガート教授は、チャットGPTに代表される生成AIについて、「データ主義による、理解なき自動化であり、科学を死に追いやるものだ」と批判しています。データ主義とは、「十分なデータを集め、十分な計算能力があれば、権威ある知識を『創造』できるという信念でありイデオロギーだ」と教授は言います。ビッグ・テックによるデータ収集と などの手法はまさにこのデータ主義に基づくビジネスモデルですが、しかし私たちはそのプロセスを見ることはできず、科学者による検証もなされません。そもそも、チャットGPTも「科学的な思考の結果」ではなく「データの組み合わせの確率からはじき出したアウトプット」に過ぎず、なぜその文章が生成されたのか、私たちはもちろん、開発した技術者ですら検証も再生もできません。「かつて宗教指導者や全体主義体制の政治指導者の言動は、科学的に検証されないまま、人々は畏怖の念をもってそれを受け容れた」と教授は論じ、生成AIも本来の科学の土壌にはいないと指摘します。今、多くの人が生成AIによる文章が正しいのかを必死でチェックしていますが、重要なのは、私たちは「生成物の真偽を確かめることしかできない」ということです。これが教授のいう「理解なき自動化」であり、「データ主義のイデオロギー」です。
さらに言えば、生成AIが結果を出すためのアルゴリズムは、私企業であるビッグ・テックが開発したものであるという問題もあります。機械学習のための膨大なデータは私たちの知らないうちに収集されているという問題、またそのデータやアルゴリズムには否応なく現実世界の差別や偏見というバイアスが入り込むという問題があります。それらが私たちには可視化されず、コントロールできないままに「結果」だけが目の前に出される─しかもそのプロセス全体が私企業の利益追求という目的のもとなされている─という根本的な問題があります。
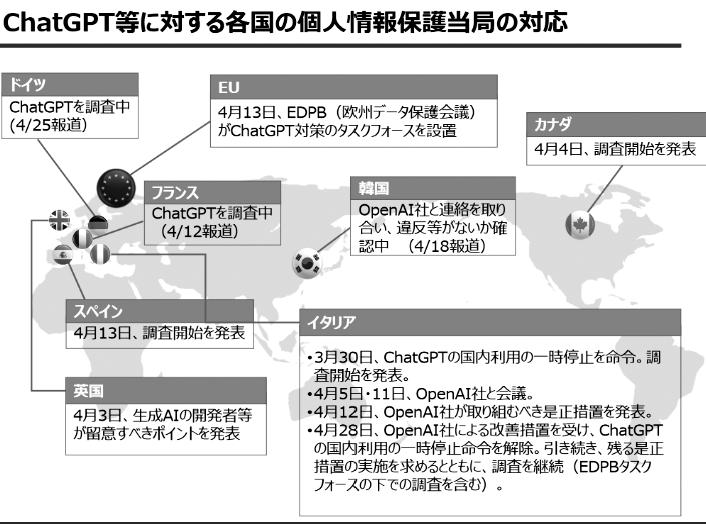
各国の規制の状況
こうした問題意識を念頭に、実際にチャットGPTが登場して以降、各国で行われている生成AIへの対応を見てみましょう。図1は、チャットGPT等に対する2023年4月時点での各国の個人情報保護当局の対応です(出典:内閣府AⅠ戦略チーム)。イタリアを中心に欧州では生成AIに対する議論が起こり、各国政府も調査を行う判断をしました。
欧州では、2010年代よりビッグ・テックによる市場独占やプライバシー侵害を規制するための一連の立法(GDPRやデジタル・サービス法、デジタル市場法など)を進め、さらに包括的なAI規制法が2023年に欧州委員会によって提案されたばかりです。チャットGPTの登場は欧州議会や官僚にも大きな影響を与え、6月14日、欧州議会はすでに審議されていたAI規制案の中にチャットGPTなど生成AIも対象にすべきとする修正案を採択しました。規制案では、AIについてのリスクを「容認できない」から「最小限」の4段階に分類し、各レベルでAIサービスの提供者とユーザーへの義務を定めています。生成AIについては、AIを使って作られた文章や画像、音声などはAIで作られたことを明示し、AIに学習させるために著作権で保護されたデータを利用した場合は公表することなど透明性の義務を課しています。違反した場合には最大で4000万ユーロ(約60億円)か、法人の場合は年間売り上げの7%のいずれかの高いほうが罰金として科されます。
米国では欧州のような包括的な規制案はありませんが、この数年でビッグ・テックによるターゲティング広告や市場の独占、大企業による 企業の買収が頻発したため業界全体の成長が見込めないなどさまざまな背景から、連邦取引委員会も規制に乗り出し、また州・自治体によるGoogleやFacebook(現・メタ)への集団訴訟、さらにはビッグ・テック内の研究者や技術者から倫理的な技術を求める運動が起こるなど、公正で透明性のある技術、市場での活動を求める気運は高まっています。
* スタートアップ企業:革新的なビジネスモデルによって社会にイノベーションを生みだすことで、起業から短期間で急成長を遂げる企業。
一方、中国もAI規制に乗り出しています。中国は2017年頃から国家戦略としてAI産業の発展を促進すると同時に、既存の法令とアルゴリズム規制、AI倫理規制と標準制定などを組み合わせる形でAI規制を行っており、中国独自のAIガバナンスモデルが形成されつつあります。2023年7月には生成AI向けに「生成人工知能サービス管理暫行弁法」が制定されました。この法律のもとでは、中国国内向けに提供する文章や画像、動画などを生成するAIについて、社会主義の価値観を反映し国家の転覆につながる内容を含んではならないほか、差別やプライバシーの侵害を防止しなければならないとされます。国家権力によるAI生成物の監視・管理といった色合いが強いものです。
さらに、国際機関も生成AIに対応しようとしています。2023年6月、国連のグテーレス事務総長は、チャットGPTなどの生成AIへの対策として、技術の規制やルールが守られているかを監視する国際機関の設置案に賛同したと発表しました。すでにAIそのものに対する規制や運用のルール形成については、OECDやG7などでも議題になりAI倫理規定を策定している他、2021年には国連教育科学文化機関(NESCO)もAI倫理勧告をつくっており、今回のチャットGPT登場に際し、改めてその完全実施を提案しています。
こうした動きからも、生成AIが私たちの産業、文化、暮らしに与える影響について各国政府や国際社会は重大に受け止めていることがわかります。それと比較すると、日本での反応・対応は不十分だと言わざるを得ません。産業界は基本的に生成AIを歓迎しており、日本も米国などの企業に負けずに生成AIの開発を促進すべきという、現実的にも無理がある生成AI推進論が多く見られます。政府も生成AIをイノベーションの源泉ととらえ、規制はもちろん他国のようにその影響を調査する動きも十分とっていませんし、罰則のないガイドラインや既存法を活用した規制(ソフトロー)を活用する方針です。
市民社会の力
欧州や米国で生成AIへの規制とそのための議論が進む背景には、市民社会の運動があります。チャットGPTのような生成AIが登場する前から、市民はプライバシー権などを中心にデジタル社会における人権侵害や差別、子どもや高齢者、障害を持つ人など脆弱な層への負の影響について指摘し続けてきました。例えば欧州のAI規制案の策定にあたっては、欧州各国で「すべての顔認識技術は人権侵害の危険があるため禁止をせよ」と市民運動が大々的なキャンペーンを展開。数百万に及ぶ署名を集め、欧州議会に提案しました。また米国でも、市警察や移民関税執行局(ICE)がドローンや監視カメラなどの顔認識技術を用いて、ブラックライブズマター(BLM)の活動家を不当に捜査したり、移民に対する長期拘留や国外退去命令などが常態化しています。こうした不当な権力行使とそれに使われる技術に対する抵抗運動も高まっています。
生成AIの懸念とは
生成AIがもたらす問題点は、大きく言って(主に法的な面から)、①著作権、②個人情報・プライバシー権、③有害情報(誤情報・偽情報・バイアス等)と言えます。①の著作権の問題には、⒜機械学習の段階で大量に集められる多種多様なデータの著作権侵害について、⒝生成AⅠによって生み出された「創作物」が既存の創作物と酷似していた場合、著作権侵害にあたらないのか、という2つの側面があります。②の個人情報・プライバシー権の問題は、チャットGPTへの指示(プロンプト)によっては、AIが何らかの形で入手し学習した個人のメールアドレスや医療情報などの要配慮個人情報を生成AIが出力してしまう危険性があります。③については、生成AIに機械学習させるデータには、私たちの現実世界に存在するさまざまな偏見や差別に満ちた内容も含まれているため、アウトプットにも予期しない形でそのバイアスが反映されてしまうことがあります。例えば、特定の宗教や人種に対する差別や、性差別や暴力的な表現をAIが生み出す可能性もあります。その場合、「これは生成AIで作成されました」との記載があるから良いという話にはなりません。誰に責任があるのか?その表現によって現実世界で被害を受けた人に対する救済措置は?など課題は多くあります。こうしたことからも、生成AIの課題は、利便性や産業推進の観点からでなく、人権や民主主義の課題や、冒頭で紹介した「科学と知識」、データ主義というイデオロギーに私たちが絡めとられていないか、という問題として理解し、対応していくべきです。
無自覚に自治体へ導入される生成AI
最後に、生成AIが公共サービスや住民の暮らしを支える基盤である自治体でどのように受け止められているかを考えます。
チャットGPTが注目され始めた後、導入に向けた調査や活用実証に乗り出す自治体が続々と登場しています。例えば2023年4月、埼玉県戸田市では「調査チーム」を設置し、チャットGPTを導入することで自治体業務の自動化・効率化が可能な領域を洗い出し、安全な利用方法を検証するとしました。神奈川県横須賀市でも、チャットGPTの活用実証として、自治体専用の「LoGoチャット」にチャットGPTのAPI機能を連携させ、すべての職員が文章の作成、要約、誤字脱字のチェック、そしてアイデア創出に活用できる環境を整備するとしました。神戸市では職員のチャットGPT利用ルールを全国初で条例化しました。さらに2023年8月、東京都庁でもチャットGPTによる業務が開始されました。利用できるのは警視庁などを除く約5万人で、職員によるアイデア出しや文書の要約・翻訳といった文書作成補助などで活用し、業務の効率化やサービス向上を目指すとしています。
今後、このように自治体業務の一部に生成AIを取り入れる自治体は増えてくると予想されます。最初は単なるアイデア出しや庁内での文書作成などかもしれませんが、これが進めば行政における政策立案や予算策定などにも援用されていくかもしれません。もちろん、いずれの自治体も、「安全な利用」のために機密情報や住民の個人情報などは取り扱わないことや、著作権保護の観点を踏まえること、そして「生成した回答の根拠や裏付けを必ず確認すること」などのガイドラインを設けています。しかしAIが生成した文書を人間が確認せよとの規律は、まさにAIの限界を示しています。AIの出した結果を入念にチェックする場合、業務軽減となるでしょうか。
さらに、行政や政治の場での政策 決定の際に、私たちが最も注意しなければならないのは、「AIは倫理性を含む決定に関する責任主体にはなりえない」という明確な事実です。例えば、行政においては、高齢者介護に予算を使ったり、高等教育の無償化を進めることなど多くの課題に優先順位を付け予算配分を行い実行する必要があります。これは単に資源の合理的な配分の問題でなく、価値の選択であり、倫理性が問題となります。これを判断するためには、責任主体となりえる人間(とその集団)が不可欠です。加えて、生成AIが成果物を出すに至ったプロセスを私たちは検証することもできなければ、そのプロセスの修正に参画することもできません。生成AIの未来の可能性について、否定するものではありませんが、自治体の存在意義と役割を考えた時、導入には最も慎重であるべきではないでしょうか。
【注】
1 ブレイン・ハガート「ChatGPT Strikes at the Heart of the Scientific World View」 https://www.cigionline.org/articles/chatgpt-strikes-at-the-heart-of-the-scientific-world-view/?fbclid=IwAR1RTB0zJxCzJK5jlYkqPQJ_hADgQOJhK1HZAFNsdphBzXLuWwEHng7u5Ik
2 内閣府ホームページ https://www8.cao.go.jp/cstp/ai/ai_team/2kai/shiryo3.pdf







